JST PRESTO Project¶
This is the home page of JST PRESTO project:
Unified Framework for Speech Privacy Protection and Fake Voice Detection
プライバシー保護と偽音声検出を統合する音声データ処理基盤
Information:
PI: Xin Wang
Period: 2023/10/01 - 2027/03/31
Research area: 社会変革に向けたICT基盤強化 Strengthening ICT Infrastructure for Social Change
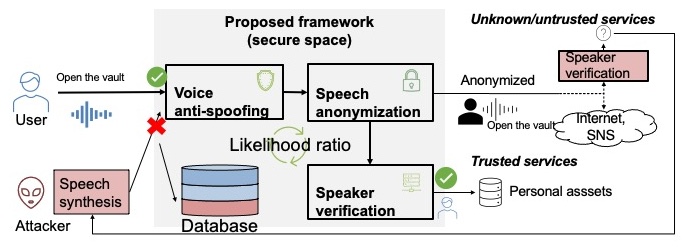
Background: The era of infodemics calls for a speech data processing system that can detect deepfake voices and anonymize speech privacy. However, existing fake voice detection and anonymization methods are independently designed, lacking joint optimization and theoretical support.
Core idea: This proposal tries to unify fake voice detection and voice anonymization within a deep learning framework based on likelihood ratios.
Outcomes¶
Research paper: see full list
Invited talk: Advances in Voice Deepfake Generation and Detection
Venue: European Association for Biometrics, Workshop on Voice Deepfakes and Adversarial Attacks Detection: Advances and Perspectives
Date: 2025/11
Place: online
Slide: NOV-13-2025.
Panel talk: voice anonymization and watermarking
Venue: APSIPA ASC 2025
Date: 2025/10
Place: Singapore
Slide: OCT-22-2025.
Research paper: ASVspoof 5: Crowdsourced Speech Data, Deepfakes, and Adversarial Attacks at Scale
Venue: Interspeech 2024
Date: 2024/09
Place: Greece, Kos
Slide: ASVSPOOF-2024.
Research paper: Revisiting score fusion for spoofing-aware speaker verification
Venue: Interspeech 2024
Date: 2024/09
Place: Greece, Kos
Slide: IS-2024.
Survey talk: Current trend in speech privacy and security
Venue: Interspeech 2024
Date: 2024/09
Place: Greece, Kos
Slide: SEP-2024.
Invited talk: Voice privacy and security issues after the boom of speech synthesis technology
Date: 2023/11
Place: Shonan Village, JP
Slide: OCT-2023.
Keynote talk: Harnessing data for improving speech spoofing countermeasures
Date: 2023/11/22
Place: NII, JP
Slide: NOV-2023.